자체 DNS 서버 구축기: 10년차 개발자가 헤츠너 한계를 넘어선 비결!
2026. 4. 18.
자체 DNS 서버 구축기: 10년차 개발자가 헤츠너 한계를 넘어선 비결!
프로덕션 환경에서 약 1,000줄의 Go 언어 코드로 자체 DNS 서버를 구축하고, 헤츠너(Hetzner) DNS에 있던 수천 개의 레코드를 성공적으로 마이그레이션했습니다. 그 결과, DNS 전파 시간이 "최대 90분"에서 "단 몇 초"로 극적으로 단축되었죠. 이 과정에서 저희는 히든 프라이머리(Hidden Primary) 패턴을 활용했고, PostgreSQL을 이벤트 버스로 삼아 AXFR 및 IXFR 방식으로 존(Zone) 데이터를 퍼블릭 세컨더리 서버로 푸시했습니다. 대체 왜, 그리고 어떻게 이런 일을 벌이게 되었는지 지금부터 자세히 풀어보겠습니다!

헤츠너 DNS가 더 이상 쓸모없었던 이유
Sliplane의 모든 서비스는 my-app-abc123.sliplane.app과 같은 관리형 서브도메인을 가집니다. 이는 실행 중인 모든 서비스마다 해당 컨테이너가 위치한 서버 IP를 가리키는 A 및 AAAA 레코드가 필요하다는 의미예요. 플랫폼이 성장할수록 레코드 수는 선형적으로 증가할 수밖에 없는 구조였죠.
저희는 헤츠너에서 대부분의 인프라를 운영하고 있었기 때문에, 무료로 제공되는 헤츠너 DNS를 사용하기 시작했습니다. 한동안은 아무 문제 없었지만, 2년이 지나자 두 가지 큰 난관에 부딪혔습니다.
레코드 제한: 헤츠너 DNS는 존(zone)당 하드캡이 존재합니다. 처음엔 500개였는데, 저희가 요청하자 감사하게도 1만 개로 늘려주긴 했습니다. 하지만 저희 플랫폼의 성장 속도를 고려하면, 몇 주 안에 이마저도 바닥날 것이 뻔했습니다. 농담 반 진담 반으로, 저희가 헤츠너에서 레코드 수 기준으로는 가장 큰 DNS 사용자 중 하나라고 하더군요. 😄
속도 문제: API를 통해 레코드를 생성하고 나면, 헤츠너 자체 네임서버에 변경 사항이 반영되기까지 최대 90분까지 걸리는 경우가 있었습니다. PaaS(Platform as a Service) 환경에서 사용자가 서비스를 배포하자마자 URL에 접속하려는 상황을 상상해 보세요. 90분 대기라니, 사용자 경험은 최악일 수밖에 없습니다. 물론 항상 그렇게 느린 건 아니었지만, 가끔이라도 이런 문제가 발생하면 사용자들은 저희 플랫폼이 고장 난 것으로 인식했고, 실제로 DNS 문제로 인해 서비스가 정상적으로 작동하지 않는 것처럼 보였습니다. 이처럼 느린 전파 시간은 플랫폼 신뢰도를 직접적으로 깎아먹는 요인이었습니다.
왜 다른 관리형 DNS 서비스를 쓰지 않았을까?
정말 합리적인 질문입니다. 대부분의 경우, 관리형 DNS 제공업체를 이용하는 것이 정답이죠. 하지만 저희처럼 특정 "규모"와 "제약 조건"을 가지고 여러 업체를 찾아다니다 보면, 금세 머리가 아파지기 시작합니다.
"영업팀에 문의하세요" 가격 정책. 저희가 필요로 하는 레코드 수를 감당할 수 있는 대부분의 업체들은 "영업팀에 문의하세요"라는 문구 뒤에 숨어 있었습니다. 제가 실무에서 여러 SaaS 솔루션을 도입하며 느낀 점 중 하나는 '영업팀에 문의하세요'라는 문구가 주는 피로감입니다. 단순한 가격표 하나 보려면 몇 주씩 미팅하고 자료 주고받아야 하는 비효율은 정말이지… 그냥 얼마인지 투명하게 알려주면 안 되나요?
레코드 또는 쿼리당 과금. 그나마 가격을 공개하는 곳들은 대개 레코드 수나 쿼리 수에 따라 과금합니다. 저희는 실제 DNS 쿼리가 얼마나 발생하는지 정확히 알 수 없었기 때문에, 이런 미지의 과금 모델로 이전하는 것은 마치 백지 수표에 서명하는 것과 같은 느낌이었습니다. 예측 불가능한 비용은 개발 조직에 큰 부담이 될 수 있죠.
EU 내 호스팅. 저희는 EU에 기반을 두고 있고, DNS 역시 EU 내에 유지하고 싶었습니다. 이 조건 하나만으로도 선택의 폭이 상당히 줄어들었습니다.
그리고 솔직히, 재미있을 것 같았습니다. 저는 약간의 컨트롤 프릭(control freak) 기질이 있는데, DNS 서버를 직접 구축하는 건 개발자들이 한 번쯤 꿈꿔볼 만한 프로젝트잖아요. 고작 천 줄 남짓한 Go 코드로 이 모든 자유를 얻을 수 있다면, 충분히 시도해 볼 가치가 있다고 생각했습니다. 결국, 직접 시스템을 만드는 데 걸린 시간은 관리형 서비스 업체와 미팅 약속을 잡는 시간보다 훨씬 짧았습니다. 😵💫
그래서 저희는 직접 만들기로 결정했습니다. 그리고 놀라울 만큼 간단하게 만들 수 있었던 비결, 바로 그 패턴을 소개합니다.
히든 프라이머리(Hidden Primary) 패턴
이 모든 과정이 제가 처음 생각했던 것보다 훨씬 간단했던 이유가 있습니다. 저희가 직접 만든 DNS 서버는 단 한 번도 공개 쿼리에 직접 응답하지 않습니다.
DNS에서 존(Zone)의 프라이머리 네임서버는 권한 있는(authoritative) 레코드를 보관합니다. 세컨더리 서버들은 AXFR(TCP를 통한 전체 존 덤프)을 사용하여 이 레코드 복사본을 가져오고, 프라이머리처럼 공개 쿼리에 응답합니다. 프라이머리에 변경이 생기면, NOTIFY 메시지를 세컨더리에 보내고, 세컨더리들은 최신 복사본을 다시 가져오게 됩니다.
히든 프라이머리는 여기서 한발 더 나아갑니다. 프라이머리 서버 자체가 외부에 공개되지 않는 것이죠. 이 서버는 오직 존 데이터를 세컨더리에 푸시하는 역할만 수행합니다. 여러분의 도메인 등록 기관에 등록된 공개 네임서버들은 모두 세컨더리 서버인 셈입니다.
이 방식을 사용하면, 저희 DNS 서버를 원하는 곳 어디든 배치할 수 있고, AXFR을 지원하는 어떤 세컨더리 프로바이더도 자유롭게 사용할 수 있습니다. 심지어 공급업체를 변경하더라도 저희 서버에는 아무런 수정이 필요 없습니다. AXFR과 NOTIFY는 표준 프로토콜이기 때문에, 어떤 규격 준수 세컨더리 서버라도 연동이 가능하여 특정 업체에 종속될 염려도 없습니다.
애니캐스트(Anycast)나 전 세계에 분산된 초고가 DDoS 방어 DNS 서버를 구축할 필요도 없었습니다. 그저 몇 대의 인스턴스로 저희 히든 프라이머리 서버를 운영하면 충분했습니다.
아키텍처
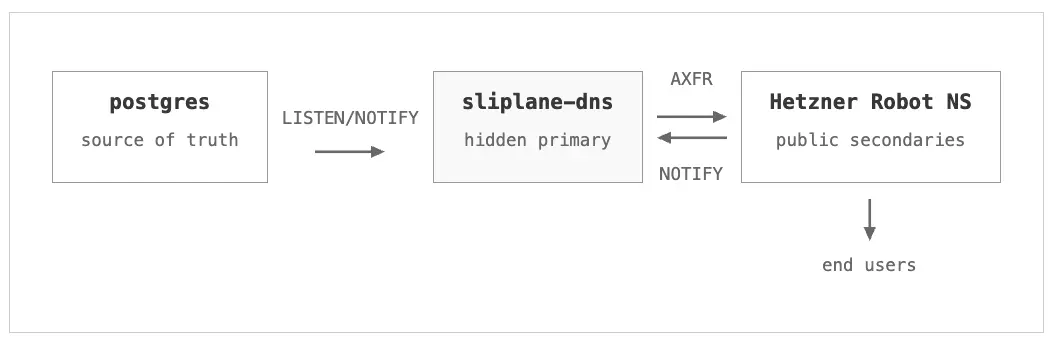
저희의 아키텍처는 놀라울 만큼 간결합니다.
PostgreSQL이 진실의 원천입니다. 서비스가 생성, 업데이트, 삭제될 때마다 pg_notify('dns_zone_changed', '')를 호출하는 트리거를 설치했습니다. 별도의 메시지 큐나 웹훅은 사용하지 않았습니다. PostgreSQL 그 자체가 이벤트 버스 역할을 하는 것이죠.
Redis, NATS, 또는 제대로 된 큐 솔루션을 사용하지 않은 이유가 궁금하실 겁니다. 두 가지 이유가 있어요. 첫째, 저희는 이미 PostgreSQL을 주 데이터베이스로 사용하고 있었기 때문에, LISTEN/NOTIFY는 "공짜" 인프라와 다름없었습니다. 새로운 것을 운영, 모니터링, 비용 지불할 필요가 없었죠. 둘째, 이벤트 볼륨이 매우 적었습니다. 피크 시간에도 존 변경은 분당 몇 번에 불과합니다. 큐 형태의 솔루션에는 턱없이 낮은 볼륨이었죠. 제가 직접 테스트해 봤을 때, 놀랍도록 간결하면서도 견고한 이벤트 처리 패턴을 제공했습니다. 덕분에 운영 복잡도를 획기적으로 줄일 수 있었어요. 이런 작은 규모의 이벤트 처리에 Kafka 같은 대형 솔루션을 도입하는 것은 엽서 한 장 보내려고 대형 컨테이너선을 빌리는 격이었습니다.
sliplane-dns는 Go 언어로 작성된 작은 서버(약 1,000줄, miekg/dns 라이브러리 기반)입니다. 이 서버는 LISTEN을 통해 PostgreSQL에 구독하고, 모든 관리 도메인과 해당 IP를 쿼리하여 DNS 존을 구성한 다음, AXFR을 통해 이를 제공합니다.
불필요한 작업을 피하기 위해 모든 레코드를 해시(hash)합니다. 만약 현재 존의 해시가 이전 존과 일치하면, 아무 일도 일어나지 않습니다. SOA 시리얼 번호도 증가시키지 않고, NOTIFY도 보내지 않죠. 존이 실제로 변경될 때만 SOA 시리얼을 업데이트하고 헤츠너의 세컨더리 IP 세 곳에 DNS NOTIFY를 보냅니다. 그러면 세컨더리들이 새로운 존을 가져가고, 레코드가 즉시 라이브됩니다.
존 전송이 실제로 어떻게 작동하는지 보려면, example.com 도메인에 단일 A 레코드만 제공하는 최소한의 AXFR 전용 DNS 서버 예시를 참고해 보세요. (전체 코드는 GitHub에서 확인할 수 있습니다.)
package main
import (
"context"
"log"
"net/netip"
"codeberg.org/miekg/dns"
"codeberg.org/miekg/dns/rdata"
)
func main() {
soa := &dns.SOA{
Hdr: dns.Header{Name: "example.com.", TTL: 3600, Class: dns.ClassINET},
SOA: rdata.SOA{Ns: "ns1.example.com.", Mbox: "admin.example.com.", Serial: 1},
}
records := []dns.RR{
soa,
&dns.A{
Hdr: dns.Header{Name: "app.example.com.", TTL: 300, Class: dns.ClassINET},
A: rdata.A{Addr: netip.MustParseAddr("1.2.3.4")},
},
soa,
}
mux := dns.NewServeMux()
mux.HandleFunc("example.com.", func(_ context.Context, w dns.ResponseWriter, r *dns.Msg) {
r.Unpack()
w.Hijack()
env := make(chan *dns.Envelope, len(records))
for _, rr := range records {
env <- &dns.Envelope{Answer: []dns.RR{rr}}
}
close(env)
dns.NewClient().TransferOut(w, r, env)
w.Close()
})
srv := dns.NewServer()
srv.Addr = ":5553"
srv.Net = "tcp"
srv.Handler = mux
log.Fatal(srv.ListenAndServe())
}
위 서버를 실행하고 dig 명령어로 존을 가져와 보세요.
dig @localhost -p 5553 example.com AXFR
example.com. 3600 IN SOA ns1.example.com. admin.example.com. 1 0 0 0 0
app.example.com. 300 IN A 1.2.3.4
example.com. 3600 IN SOA ns1.example.com. admin.example.com. 1 0 0 0 0
전체 존 전송은 단순히 SOA 레코드를 시작으로, 모든 레코드, 그리고 다시 SOA 레코드로 마무리되는 형태입니다. 헤츠너의 세컨더리 서버들이 저희 프로덕션 서버에서 가져가는 데이터도 이와 비슷하지만, 두 개의 SOA 레코드 사이에 수천 개의 레코드가 더 들어있는 형태라고 보시면 됩니다.
토요일 밤의 DNS 수술
DNS 네임서버는 점진적으로 마이그레이션할 수 없습니다. 등록 기관에 있는 NS 레코드는 이전 세트를 가리키거나, 새로운 세트를 가리키거나 둘 중 하나여야 합니다. 중간에 단절되는 전환 구간이 발생할 수밖에 없죠.
저희는 헤츠너의 네임서버(hydrogen.ns.hetzner.com, oxygen.ns.hetzner.com, helium.ns.hetzner.de)에서 헤츠너 로봇(Hetzner Robot)의 세컨더리 네임서버(ns1.first-ns.de, robotns2.second-ns.de, robotns3.second-ns.com)로 전환해야 했습니다.
전환 기간 동안, 캐시된 이전 NS 레코드를 가지고 있는 리졸버들은 여전히 이전 서버에 쿼리하여 TTL이 만료될 때까지 오래된 데이터를 얻게 될 것입니다. 두 가지 요인이 이 문제를 관리 가능한 수준으로 만들었습니다. 첫째, NS 위임 TTL이 5분으로 짧았고, 둘째, 이 기간 동안 새로 배포된 신규 서비스만 영향을 받았습니다. 기존 A/AAAA 레코드는 두 네임서버 세트 모두에서 동일했거든요.
저희는 플랫폼 활동이 가장 적은 토요일 밤에 작업을 진행했습니다. 결과는 순조로웠고, 다행히 사용자 불만은 단 한 건도 없었습니다!
우리를 괴롭혔던 한 가지: IXFR
처음에는 AXFR만으로 충분하다고 생각했습니다. 모든 튜토리얼과 예제에서 보여주는 프로토콜이고, 저 역시 가장 먼저 구현한 것이 AXFR이었으니까요. 전체 존을 덤프하고, 시작과 끝에 SOA 레코드를 넣으면 끝이라고 생각했습니다.
하지만 헤츠너 로봇의 세컨더리 서버는 AXFR만 사용하지 않았습니다. 이미 존 데이터를 가지고 있는 상태에서 NOTIFY 메시지를 통해 새로운 SOA 시리얼을 확인하면, 우선 증분 존 전송(Incremental Zone Transfer, IXFR, RFC 1995), 즉 이전 시리얼 이후 변경된 레코드들의 차이점만을 요청합니다. 만약 프라이머리가 IXFR을 지원하지 않으면, 정상적으로 동작하는 세컨더리는 AXFR로 폴백(fallback)해야 합니다. 그런데 헤츠너 로봇은 특정 상황에서 이 폴백이 깔끔하게 이루어지지 않는 경우가 있었고, 저희가 IXFR을 구현하기 전까지는 존 업데이트가 제대로 되지 않는 문제가 발생했습니다.
사실 이 부분은 저도 실무에서 직접 경험해 보지 않았다면 놓치기 쉬운 디테일입니다. 프로덕션 환경에서 예상치 못한 문제가 발생했을 때, 스펙 문서를 다시 파고들어 미묘한 프로토콜 동작 차이를 찾아내는 과정은 정말이지… 짜릿하면서도 피곤한 작업이죠. IXFR 구현은 그리 어렵지 않습니다. 단순히 최근 존 버전들의 작은 히스토리를 유지하고 있다가, 요청이 들어오면 클라이언트의 시리얼과 현재 시리얼 사이의 델타(변경분)를 반환하면 됩니다. 하지만 이런 종류의 문제는 실제 세컨더리 서버에 배포해보고 나서야 발견할 수 있는 종류의 것이죠. 이 RFC를 작성한 분께 경의를 표합니다!
가치 있는 투자였을까?
지금까지는 100% 가치 있는 투자였다고 확신합니다. 전파 시간은 "최대 90분"에서 존 전송에 걸리는 시간, 즉 저희 존 크기에서는 사실상 즉시 반영되는 수준으로 단축되었습니다. 플랫폼이 성장하더라도 레코드 제한에 부딪힐 일 없이 존이 함께 커나가고, 시스템 전반에 걸쳐 완전한 가시성(observability)까지 확보할 수 있었죠.
당신도 직접 구축해야 할까?
아마 아닐 겁니다. 대부분의 경우, Cloudflare DNS, Route 53, 또는 여러분의 클라우드 제공업체가 제공하는 관리형 DNS 서비스를 사용하는 것이 현명합니다. 빠르고, 잘 작동하며, 여러분이 신경 쓸 필요가 없으니까요.
하지만 만약 당신도 관리형 DNS 제공업체의 한계에 부딪히게 된다면, 이 히든 프라이머리 패턴은 반드시 알아둘 가치가 있습니다. 프라이머리 서버를 공개할 필요가 없고, 어떤 AXFR 호환 세컨더리 서버도 사용할 수 있으며, 심지어 제공업체를 변경하더라도 자체 서버를 수정할 필요가 없다는 강력한 장점을 가지고 있으니까요.
건강하게 개발하시길!
요나스, Sliplane.io 공동 창립자
원문: https://dev.to/code42cate/how-we-built-our-own-dns-server-4d3k 수집일: 2026-04-18 01:11:57